
Intro to RAG and UX
Bridging Advanced AI with User-Centered Design


Large Language Models (LLM), like ChatGPT and its brethren, are powerful tools. This we know.
Yet for all their usefulness, they still have a major problem—they’re liars. Damn good ones too.
Ask them nearly anything, and they’ll likely spit out a well-constructed, coherent, and conversational answer. But that answer has a high probability of being partial or total BS.
That’s because LLMs like ChapGPT are designed to be convincing, but not necessarily factual. Part of this stems from the fact that they’re trained on closed datasets, with ChatGPT’s knowledge ending in 2022.
But there are technologies addressing this problem, and as tech workers, it behooves us to understand them.
You already know LLM and GPT, so make room in your brain for yet another AI-related, three-letter acronym.
Allow me to introduce you to RAG.
What is RAG?
RAG stands for Retrieval Augmented Generation. It’s a framework/process/technique that makes LLM responses more reliable and accurate by retrieving related and up-to-date data that’s relevant to a user’s query.
It combines the power of both retrieval- and generative-based AI models to produce better results.
Think of it this way.
Imagine you’re in a library, looking for a specific book. Not only do you have access to the stacks, but there’s another helpful resource that makes the process easier—the librarian.
That librarian can not only guide you to the right section, but also help you find related material, or even give you a summary of resources tailored to your interests. This is a bit like how RAG makes an LLM more effective.

Or, think of it like a plug-in.
Figma on its own is an excellent piece of software, but layering on your favorite plug-in makes it even better.
RAG is like a plug-in for LLMs—an additional layer that enhances their capabilities and usefulness.
Components of a RAG system
The RAG technique or process has three major components: retrieval, generation, and data sources. Here’s a quick breakdown.
Retrieval
Makes use of vector databases, which store data in a way that allows for efficient retrieval based on the similarity of information.
Semantic search: utilizes natural language understanding to fetch the most relevant documents or pieces of information from the database.
Generation
Large Language Models generate human-like text based on the retrieved information, ensuring that the output is coherent and contextually appropriate.
Data sources
Documents: includes textual data such as articles, research papers, and books.
Databases: structured data sources like SQL databases.
APIs: real-time data from various web services and applications.
Typical workflow of a RAG system
User query: the process starts when a user inputs a query or request.
Retrieval: semantic search is used to find the most relevant information from the vector database and other data sources.
Augmentation: the retrieved information is then fed into the generation component (the LLM).
Generation: the LLM processes the information and generates a coherent response tailored to the user's query.
Output: the system delivers the generated content to the user, providing a relevant, personalized, and (hopefully) accurate response.
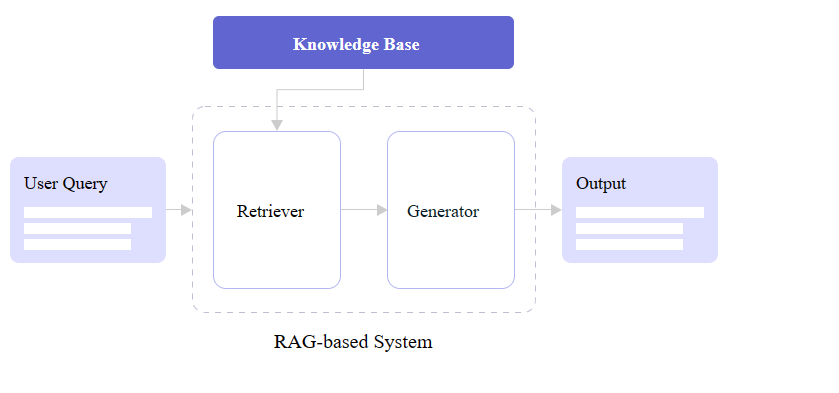
Diagramming the integration of retriever and generator components from “A Simple Guide To Retrieval Augmented Generation Language Models”
Rag in UX
So how can RAG help us create better user experiences?
Imagine you walk into your local coffee shop. The barista sees you and not only remembers your usual order, but also suggests a new blend you might enjoy based on your past orders and even your current mood.
RAG can help us deliver this kind of personalized experience efficiently and at scale—much better than an LLM like ChatGPT can on its own.

So let’s explore some possibilities for RAG in UX across different fields with examples and use cases.
UX use cases for RAG
Customer support chatbots
Example: A chatbot integrated with a company's internal knowledge base to provide accurate and up-to-date responses to customer queries.
Use case: Enhancing customer service by retrieving relevant information from knowledge base texts, policy documents, FAQs, user manuals, etc. to give users specific and accurate answers to their questions with incredible speed and accuracy.
E-commerce
Example: An internal system that can access and analyze product data, user reviews, and individual user data.
Use case #1: Better, faster, and more accurate product descriptions across the site.
Use case #2: User-specific, customized product descriptions based on purchase and browsing history. The system could change the order of images and product details at the level of the individual user, showing users the things that matter most to them first.
Medical assistants
Example: A generative AI model supplemented with a medical index.
Use case: Assisting medical staff by providing precise information from medical databases, research papers, and patient records to support clinical decisions.
Deploying RAG systems in this context could have far-reaching benefits, reducing medical error and thus reducing medical malpractice suits and lowering insurance costs.
Financial analysis tools
Example: An AI assistant with access to market data and financial reports.
Use case: Helping financial analysts make more informed decisions by retrieving insights from up-to-date market trends, financial statements, and economic indicators, and then generating actionable insights.
Employee training and productivity
Example: AI systems that access technical manuals, training videos, and logs.
Use case: Enhancing employee training programs and improving productivity by providing contextual information and step-by-step guidance based on the latest company protocols and procedures.
Legal research assistants
Example: A legal AI assistant that retrieves case law, statutes, and legal precedents.
Use case: Supporting lawyers and judges by providing relevant legal information and precedents to aid in case preparation and decision-making.
Vacation rental information systems
Example: A chatbot providing contextual information about vacation rentals.
Use case: Offering detailed, fact-based answers about amenities, accessibility, and local attractions for potential renters.
RAG for a UX content style guides
The above are some hypothetical or potential use cases for RAG in UX. But here’s a content style guide RAG app (slow loading) we’re already implementing for one of the client of the UX Writing Hub (the UX training and agency company I’ve been running for the past 6 years).

This RAG app has been trained on a style guide for a client named Beti, a cloud-based platform for construction site management.
It allows the people at the team of Beti to easily query the style guide to get answers on how to follow it.
On the front end, it seems like good old ChatGPT, while on the back end, it's a trained RAG that can answer questions related only to the style guide itself, and it gets almost zero hallucinations and knows how to generate to a piece of microscopy based on the style guide rules.
Next week, I’ll share a step-by-step case study for building this type of RAG.
RAG in UX summary
We stand at the cusp of a technological upheaval whose scale and impact we can’t yet fully perceive.
LLMs like ChatGPT changed our world seemingly overnight. But when coupled with other technologies, the possibilities will only continue to expand.
As UX professionals and technology workers, it’s our duty to not only keep up with the latest developments, but to constantly consider how their implementation can affect the user experience.
So, considering what you now know about RAG, how might you implement this type of system into the products you work on?
Let me know!
Written by Yuval Keshtcher, Edited by Aaron Raizen